
Fixed, Mixed, and Random Effects: The Ecology Edition

Image Credit: WomEOS, CC BY-SA 2.0, Image Cropped
I’ve written about fixed, mixed, and random effects in linear models before (and others have too) but I think it’s time to approach the topic with some ecology motivation. What do these different types of effects mean to us in the wild and when might we need to use one over the other? Read on to learn more!
Let’s take a motivating example from an Ecology for the Masses reader. Suppose we want to understand the variation in species richness across a variety of locations. However, our locations aren’t just random ones across a landscape; we are collecting observations at different locations, within different wetlands, which are themselves located in different parks. This gives us a ‘nested’ structure. We also have a likely relationship between observations within a particular wetland and within a particular park. But uh oh, non-independence between observations is the enemy of the simple linear model. What do we do?
One strategy is to aggregate the data at each level. In this case we could take the average species richness within a wetland and see how those observations vary within a single park. We could then take this same approach for each park separately. However, by taking an average across many observations within a wetland, we’re potentially missing out on a lot of interesting variability. In addition, studying one park at a time doesn’t let us share information across multiple parks, and you know what they say, less data more problems.
Fixed and random effects (or a mix of the two) can help us use every hard-won data point by helping us account for the non-independence that comes from known structure in the data. That way any variation left over after we’ve accounted for that structure (residual variation) is the uncorrelated kind, which is the kind we need when we’re relying on a linear model to tell us about the data.
Great, but what are these different types of effects? A fixed effect is well, fixed. It’s a parameter that we estimate that accounts for the effect of a particular category. Here we might want to know the average species richness per wetland. A fixed effect is essentially an intercept term for the categorical variable, “wetland.” This approach makes sense when we have data from every wetland in the park and we are interested in actually knowing how different wetlands differ on average.
However, sometimes we just know there is a relationship between data points based on where the data comes from, but we don’t actually care about estimating an effect. We just want to account for that structure in the data. Random effects are, you guessed it, random. They are parameters that are defined as random variables, typically assumed to come from a normal distribution with mean zero and an unknown variance. This means we actually care about estimating the variance that relates all of them together rather than estimating the actual value for each.
Let’s be more concrete. Take the different parks in our setup. Unlike for wetlands, where we may have observations for every wetland in a park, we have likely not collected data at every park in the country. We just have a subset of this broader population of parks. We know there is likely a relationship between data points collected in different parks, but we aren’t really interested in knowing what the particular park effects are for the parks in our sample. We just want to account for any variability between parks in our model. This would be a good time to use a random effect to represent “park” as a category.
So far, what do we have in math? We have species richness R indexed by park p and wetland w. We’ve broken it up into a fixed effect (beta) indexed by w and a random effect (alpha) indexed by p. We are then assuming that the leftover variation (epsilon, indexed by both p and w) is uncorrelated, heteroscedastic, and normal error a la Ordinary Least Squares.
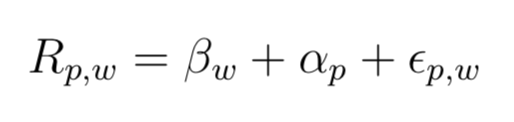
What if we did want to know the park effects? Could we just have two fixed effects? That depends on the data we have access to. In order to estimate a coefficient for each wetland and park we’d need multiple observations per wetland and observations for multiple wetlands per park. Without that replication at each level of the nested structure, the coefficients between different wetlands and parks would start to bleed into one another.
What if we didn’t care about the wetland effects either? Could we have two random effects? This is a bit trickier because we would need to assume the two random effects are independent of one another in order to disentangle the variability induced by park from the variability induced by wetland. However, this independence can be hard to verify.
What about that normal distribution assumption for the random effects? Is that ever a deal breaker? The normal distribution assumption is made primarily for computational and mathematical convenience, so you’ll see many tools for fitting these kinds of models (like R’s lme4) make this assumption. However, there are diagnostics that can help you determine whether this assumption is plausible for your data (think a repurposed quantile-quantile plot for the random effects themselves). And if you had reason to believe this assumption wasn’t met, it is possible to implement your own hierarchical model that assumes the random effect comes from, for example, a Student t’s distribution.
So I hope that gives you something to go on. When deciding between fixed and random effects we just have to think carefully about the data-collection (what is the structure) and our goals for analysis (what do we want to estimate).
Have a quantitative term or concept that mystifies you? Want it explained simply? Suggest a topic for next month below of contact Sara directly on Twitter → @sastoudt.

Pingback: “Those Things Are Evil”: Prediction Intervals in Mixed Models | Ecology for the Masses
Pingback: Farewell to the Stats Corner | Ecology for the Masses